
Innovation Roundup
Innovation Roundup
A newsletter about innovation, technology, health economics, regulation and empathy in medicine (9/14/23)
Welcome to the latest issue of our newsletter. Here is what we have in store this week:
In Science Roundup, we tackle the promise and pitfalls of using electronic health record (EHR) data for biomarker discovery. With its vast datasets and diverse variables, the EHR system can be a goldmine for digital biomarker discovery. But, like any treasure hunt, there are challenges—ranging from data biases to interoperability issues. We discuss several strategic measures to counteract these issues, from crafting effective phenotyping algorithms to enhancing data collection.
In Industry Roundup we tackle a critical question: "Are Digital Health Solutions Actually Solutions?" It's a topic that promises to be at the forefront of future research collaborations between industry and academia.
Meanwhile, in Healthcare Economics and Policy Roundup we talk about Virtual First Care (V1C) and a toolkit you won't want to miss.
Lastly, in Regulatory Roundup, we dive deep into the complex world of regulating large language models in healthcare. With the FDA seeking to balance innovation with oversight, we touch on key considerations, from data privacy to continuous monitoring.
Join us as we delve into these topics and more, and gear up for a stimulating discussion on LLMs at the upcoming HRX roundtable!
Science Roundup
Opportunities and challenges for biomarker discovery using electronic health record data.
This paper came in at the right time as we are currently thinking about several projects within our EHR system.
Electronic health record (EHR) data are an attractive for (digital) biomarker discovery due to their large sample sizes, diverse population, availability of longitudinal data, cost-effectiveness, and availability of many different clinical variables:
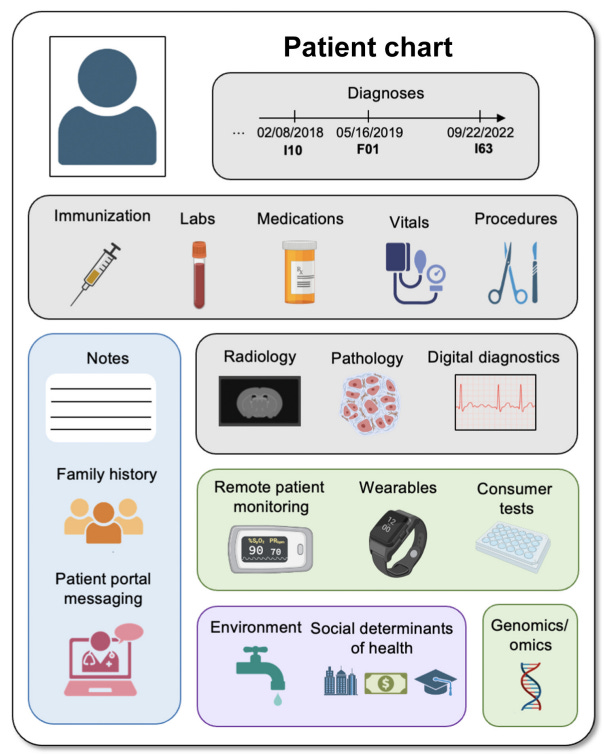
These combined with advanced data transformation and analytical techniques allow for construction of robust biomarker discovery workflows using EHR and wearable data.

However there are several limitations using EHR data for biomarker discovery:
EHRs not designed for research: This means that the data within EHRs may not align directly with research goals, leading to potential biases and limitations.
Availability and bias of EHR data
Missing data: EHRs may have missing data, which can limit the completeness and accuracy of the information available for biomarker identification.
Limited data elements: Some important data elements, such as family history, lifestyle and behavior, and medication compliance, may not be comprehensively collected in EHRs. This can limit the ability to capture all relevant factors for biomarker identification.
Lack of diversity in EHR populations: Many EHR populations, especially those linked to DNA biobanks, are predominantly of European ancestry. This lack of diversity may lead to findings that do not accurately translate to other populations, highlighting the need for analyzing data from large, diverse populations.
Data quality and interoperability: Ensuring the quality and consistency of EHR data across different healthcare systems and institutions can be challenging. Interoperability issues can hinder the integration and analysis of data from multiple sources.
These challenges can be tackled using several strategies:
Developing phenotyping algorithms: Creating algorithms that extract disease phenotypes from structured clinical data, such as International Classification of Diseases (ICD) codes, Clinical Procedural Terminology (CPT) codes, vital signs, clinical lab measurements, medications, and unstructured data from clinical notes processed through natural language processing (NLP).
Collaborating with clinical experts: Working closely with clinical experts to understand when specific lab tests would and would not be ordered, and generating heuristics to look at individual values in their larger context.
Enhancing data collection: Considering enhancing data collection in the clinic to capture important social determinants of health (SDOH) measures, such as sexual orientation and geolocation data, which are currently lacking in EHRs.
Addressing missing data: Mitigating the effects of missing data in EHRs by employing methods to impute missing values or account for missingness in the analysis.
Industry Roundup
Are Digital Health Solutions Actually Solutions?
This is article is asking the question that is on everyone’s mind: are these digital health solutions a worthwhile investment?

I think this will be a very important area for research in the coming years. It will require a close partnership between industry and academic centers to establish standards and publish evidence showing robustness or lack thereof digital health solutions.
Healthcare Economics and Policy Roundup
This is an indispensable Payment & Coding Toolkit to show providers, investors, payers, policymakers, and other stakeholders how to get paid for offering virtual first care (V1C) services!“
What is V1C ? Virtual first care (V1C) is medical care for individuals or a community accessed through digital interactions where possible, guided by a clinician, and integrated into a person's everyday life.
I am definitely bookmarking this !
Regulatory Roundup
The imperative for regulatory oversight of large language models (or generative AI) in healthcare
I have preparing for a roundtable at HRX discussing various topics on LLMs and this paper seemed timely. The FDA is in tough spot as usual, trying to strike a right balance between regulation and innovation. I think we all agree that the regulation of large language models (LLMs) in healthcare should differ from the regulation of other AI-based medical technologies due to their unique characteristics and potential risks. LLMs, such as natural language processing models, have the ability to process and generate human-like text, which can be used for various healthcare applications like clinical decision support systems, medical chatbots, and electronic health record analysis. Here are some considerations for regulating LLMs in healthcare:
Data privacy and security: LLMs require access to large amounts of patient data to train and improve their performance. Regulations should ensure that patient data is handled securely, with strict privacy measures in place to protect sensitive information.
Transparency and explainability: LLMs are often considered black boxes, making it challenging to understand how they arrive at their decisions or recommendations. Regulations should require LLM developers to provide transparency and explainability mechanisms, enabling healthcare professionals to understand the reasoning behind the model's outputs.
Bias and fairness: LLMs can inadvertently learn biases present in the data they are trained on, leading to biased outputs. Regulations should address the need for bias detection and mitigation strategies to ensure fair and equitable healthcare outcomes for all patients.
Validation and evaluation: LLMs should undergo rigorous validation and evaluation processes to assess their performance, accuracy, and safety before deployment in healthcare settings. Regulations should outline the standards and criteria for evaluating LLMs to ensure their reliability and effectiveness.
Continuous monitoring and updates: LLMs should be continuously monitored to detect any performance degradation, biases, or safety issues that may arise over time. Regulations should require regular updates and maintenance of LLMs to ensure their ongoing safety and effectiveness.
I am excited to discuss this further next week !
Art of the week

The Nurture of Jupiter, Nicolas Poussin, Mid-1630s
Dulwich Picture Gallery, London, United Kingdom
This is from the one and only Ted Gioia. His Substack is one of my favorites and I highly recommend it for the culturally curious. This has inspired me to write a similar (aspirational) treaty for myself! The big lesson here : There are no shortcuts to wisdom
WHAT YOU LEARN IN CLASSROOMS IS IRRELEVANT, AND SOMETIMES EVEN WORTHLESS—YOU MUST TAKE RESPONSIBILITY FOR YOUR OWN EDUCATION
When I was in high school, I got up at 5:30 AM so I could read a long time before going to my first class. Over the course of my life, my daily schedule starts with reading and ends with reading—and there are blocks of reading during the day.
There have been times in my life when I had to work demanding jobs, with late hours and constant deadlines. But I always found time to read for an hour or so before starting work in the morning. This frequently cut into my sleep or forced me to make other sacrifices.
Thank you again for reading my newsletter.
If you enjoy reading this newsletter, please share it with someone else who might enjoy reading it.
Talk soon,
Hamid